以前的文章介绍了 chromedp 进行浏览器网页截图, 这次介绍一种新的网页截图的方法——即使用 playwright 进行浏览器网页截图。
playwright 介绍#
Playwright是一个用于自动化浏览器操作的开源工具集。它由微软开发并于2020年发布,旨在提供一种跨浏览器、跨平台的解决方案,可用于测试Web应用程序、编写爬虫、执行自动化任务等。
Playwright支持多种主流浏览器,包括Chrome、Firefox、Safari和Edge,它提供了一组简单易用的API,可以模拟用户与Web页面的交互行为,例如点击、填写表单、导航等。与其他类似工具相比,Playwright的一个重要特点是它的跨浏览器支持,这意味着你可以使用相同的代码在不同浏览器上运行你的自动化任务,而不需要为每个浏览器单独编写代码。
Playwright还提供了强大的调试功能,可以帮助开发人员在自动化过程中定位和解决问题。它支持截图和录制操作,使得调试变得更加直观和高效。
另外,Playwright还具有一些高级功能,例如可以模拟不同的设备、网络环境和地理位置,以及支持并发执行多个浏览器实例等,这些功能使得它在编写复杂的自动化任务时非常有用。
由于我日常主要使用 go 语言进行开发,所以本文的内容主要以 playwright 的 go 模块 playwright-go 为主要介绍。
1
| go get -u github.com/playwright-community/playwright-go
|
安装相关浏览器和操作系统依赖项:
1
2
3
4
| go run github.com/playwright-community/playwright-go/cmd/playwright@latest install --with-deps
# Or
go install github.com/playwright-community/playwright-go/cmd/playwright@latest
playwright install --with-deps
|
也可以在代码中使用以下代码安装: err := playwright.Install()
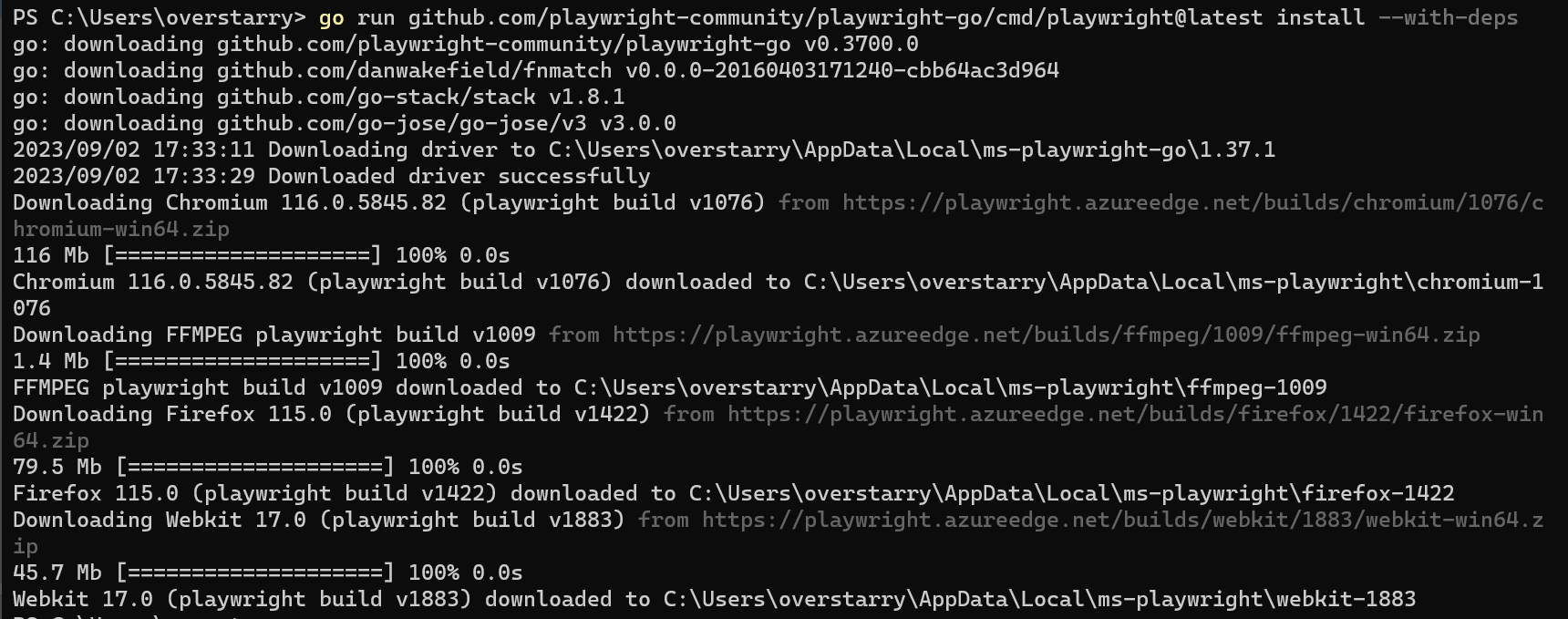
通过安装截图可以看出安装了3大主流浏览器和ffmpeg。
接下来我们看一个官方的例子,从Hacker News中抓取当前投票最高的项目。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
package main
import (
"fmt"
"log"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
browser, err := pw.Chromium.Launch()
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
page, err := browser.NewPage()
if err != nil {
log.Fatalf("could not create page: %v", err)
}
if _, err = page.Goto("https://news.ycombinator.com"); err != nil {
log.Fatalf("could not goto: %v", err)
}
entries, err := page.Locator(".athing").All()
if err != nil {
log.Fatalf("could not get entries: %v", err)
}
for i, entry := range entries {
title, err := entry.Locator("td.title > span > a").TextContent()
if err != nil {
log.Fatalf("could not get text content: %v", err)
}
fmt.Printf("%d: %s\n", i+1, title)
}
if err = browser.Close(); err != nil {
log.Fatalf("could not close browser: %v", err)
}
if err = pw.Stop(); err != nil {
log.Fatalf("could not stop Playwright: %v", err)
}
}
|
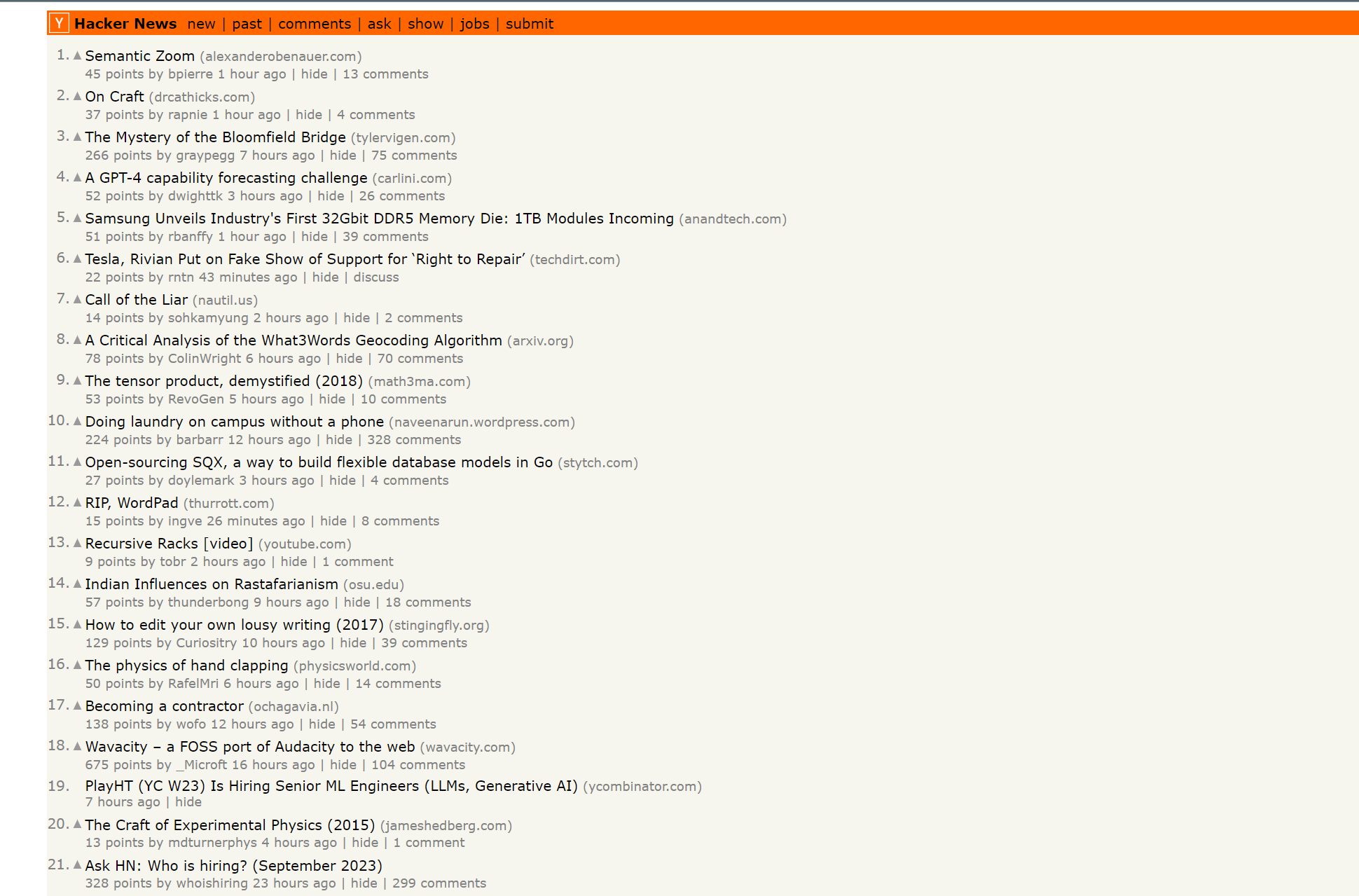
运行代码后,输出:

可以看到当前排名最高的30个项目成功输出了。
接下来介绍如何进行网页截图。
截取网站地图页面的截图#
接下来我们根据 overstarry.vip 的网站地图获取每个页面的截图。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| package main
import (
"encoding/xml"
"fmt"
"github.com/playwright-community/playwright-go"
"io"
"log"
"net/http"
"time"
)
type Urlset struct {
XMLName xml.Name `xml:"urlset"`
Xmlns string `xml:"xmlns,attr"`
Urls []Url `xml:"url"`
}
type Url struct {
Loc string `xml:"loc"`
Lastmod string `xml:"lastmod"`
}
func main() {
sites := formatSiteXml("https://overstarry.vip/sitemap.xml")
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not launch playwright: %v", err)
}
browser, err := pw.Chromium.Launch()
if err != nil {
log.Fatalf("could not launch Chromium: %v", err)
}
page, err := browser.NewPage()
if err != nil {
log.Fatalf("could not create page: %v", err)
}
for _, site := range sites {
if _, err = page.Goto(site, playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateDomcontentloaded,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
if _, err = page.Screenshot(playwright.PageScreenshotOptions{
Path: playwright.String(fmt.Sprintf("./img/%d.png", time.Now().Unix())),
}); err != nil {
log.Fatalf("could not create screenshot: %v", err)
}
}
if err = browser.Close(); err != nil {
log.Fatalf("could not close browser: %v", err)
}
if err = pw.Stop(); err != nil {
log.Fatalf("could not stop Playwright: %v", err)
}
}
func formatSiteXml(sitemapURL string) []string {
resp, err := http.Get(sitemapURL)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bytes, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
var urlset Urlset
err = xml.Unmarshal(bytes, &urlset)
if err != nil {
log.Fatal(err)
}
urls := make([]string, 0)
for _, url := range urlset.Urls {
urls = append(urls, url.Loc)
}
return urls
}
|
这段代码主要是先获取本站的所有页面,然后对每个页面进行截图。代码运行完,查看截图时发现截图的大小不是完整的页面内容,只有部分可视大小,查看源码发现需要设置 FullPage 参数,才能截取完整页面。